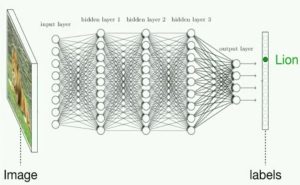
Estudo do MIT mostra que cientistas estão treinando Inteligência Artificial tudo errado
Se você ainda não é assinante, assine. A newsletter do MIT chamada The Algorithm é sensacional. Não perco nada. Aqui, um estudo dos cientistas do centro de pesquisas deles, que revela que eles mesmos, cientistas, andam over-treinando as redes neurais de forma desnecessária, gastando muito mais tempo, dinheiro e, nem sempre, chegando aos melhores resultados.
| Hello Algorithm readers, |
|

COMPARTILHE:








